目录
一、问题描述
二、发现机制
三、解决策略分析
(一)解决策略一:多级缓存策略
客户端本地缓存
代理节点本地缓存
(二)解决策略二:多副本策略
(三)解决策略三:热点 Key 拆分与动态分散
四、总结
干货分享,感谢您的阅读!
在高并发场景下,缓存作为前置查询机制,显著减轻了数据库的压力,提高了系统性能。然而,这也带来了缓存失效、增加回溯率等风险。常见的问题包括缓存穿透、缓存雪崩、热Key和大Key等。这些问题如果不加以处理,会影响系统的稳定性和性能。因此,采用有效的缓存策略,如缓存空结果、布隆过滤器、缓存过期时间随机化、多级缓存等,对于保障系统在高并发情况下的可靠性至关重要。本次我们将详细探讨热点key及其应对策略。
历史缓存热门问题回顾:
| 热门问题 | 具体分析和解决方案 |
| 缓存穿透 | 高并发场景下的缓存穿透问题探析与应对策略-CSDN博客 |
| 缓存雪崩 | 高并发场景下的缓存雪崩探析与应对策略-CSDN博客 |
| 缓存击穿 | 高并发场景下的缓存击穿问题探析与应对策略-CSDN博客 |
| 大 Key问题 | 高并发场景下的大 Key 问题及应对策略-CSDN博客 |
| 热点Key发现机制 | 优化分布式系统性能:热key识别与实战解决方案-CSDN博客 |
一、问题描述
热点 key 问题是指某些数据的访问量非常高,超过了缓存服务器的处理能力。这种现象在电商促销、社交媒体热点等场景中特别常见。热点 key 问题主要有以下几个方面:
- 流量集中,达到物理网卡上限:当大量请求集中到某个热点 key 时,这些请求会被路由到相同的缓存服务器。随着流量增加,服务器的物理网卡可能达到带宽上限,无法再处理更多请求。
- 请求过多,缓存分片服务被打垮:缓存系统通常使用分片机制来分担负载。然而,热点 key 的访问量可能过高,单个分片无法处理,导致该分片服务被打垮。
- 缓存分片打垮,重建再次被打垮,引起业务雪崩:当某个缓存分片被打垮后,系统可能会尝试重建该分片。然而,重建过程中的负载再次集中到该分片上,导致分片再次被打垮,形成恶性循环,引起业务系统的雪崩。
二、发现机制
本部分可直接见:优化分布式系统性能:热key识别与实战解决方案-CSDN博客
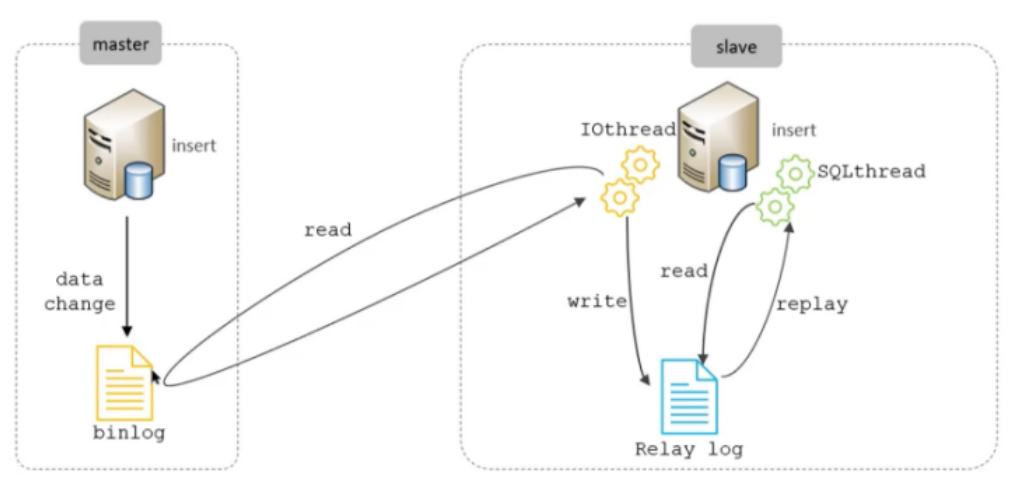
在现代分布式系统中,热key问题已经成为影响系统性能和稳定性的重要因素之一。热key,指的是在分布式缓存系统中某些特定的key被频繁访问,导致这些key所在节点的负载过高,甚至可能导致系统瓶颈或崩溃。尽管我们可以通过本地缓存、热key备份和迁移等方式来解决热key问题,但如果热key已经出现而没有及时发现和处理,问题将变得更加棘手。因此,如何提前发现并及时处理热key,是保障系统稳定性和性能的关键。
通过人为预测,客户端监控,机器层面监控,Redis服务端Monitor以及热点发现系统等多种手段,可以及时识别并处理潜在的热点key。每种解决方案都有其独特的优势和局限性,应根据具体业务场景选择合适的策略进行实施。
在实施过程中,需要关注解决方案的实时性、成本效益以及对现有系统的影响。同时,建议采用综合的监控和预测机制,持续优化和调整策略,以确保系统在面对高并发和复杂业务场景时能够稳定可靠地运行。热key问题的解决不仅是技术层面的挑战,更是对系统架构设计和运维管理能力的综合考验。通过有效的热key管理,可以提升系统的响应速度和整体性能,为用户提供更加稳定和高效的服务体验。
三、解决策略分析
(一)解决策略一:多级缓存策略
多级缓存策略通过在客户端和服务端都设置缓存层,以便将缓存离用户更近,从而减少对远程缓存服务器的访问。
客户端本地缓存
在客户端加入本地缓存,如使用 Guava Cache 或 Ehcache,热点数据可以直接命中本地缓存,从根本上减少热点请求到缓存服务的次数。
- 优点:减少网络延迟,提高缓存命中率,降低远程缓存服务器压力。
- 缺点:容量有限,容易受到业务数据的入侵。
可以通过改造 Redis SDK 集成本地缓存功能,从而对业务代码无感知:
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
/**
* @program: zyfboot-javabasic
* @author: zhangyanfeng
* @create: 2013-03-23 22:33
**/
public class LocalCache {
private static final LoadingCache<String, String> localCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) throws Exception {
// 默认返回空值,可以改为从远程缓存或数据库加载数据
return null;
}
});
public static String get(String key) {
try {
return localCache.get(key);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
public static void put(String key, String value) {
localCache.put(key, value);
}
public static void main(String[] args) {
// 示例:设置和获取本地缓存
LocalCache.put("hot_key", "hot_value");
System.out.println("Local cache value: " + LocalCache.get("hot_key"));
}
}
代理节点本地缓存
如果缓存集群为代理模式,可以在代理节点上添加本地缓存。代理节点可以水平扩展,通过分散压力解决容量有限的问题。
- 优点:缓存容量可以扩展,通过代理节点减少远程缓存服务器的压力。
- 缺点:性能稍逊于客户端本地缓存,因为代理节点距离用户较远。
(二)解决策略二:多副本策略
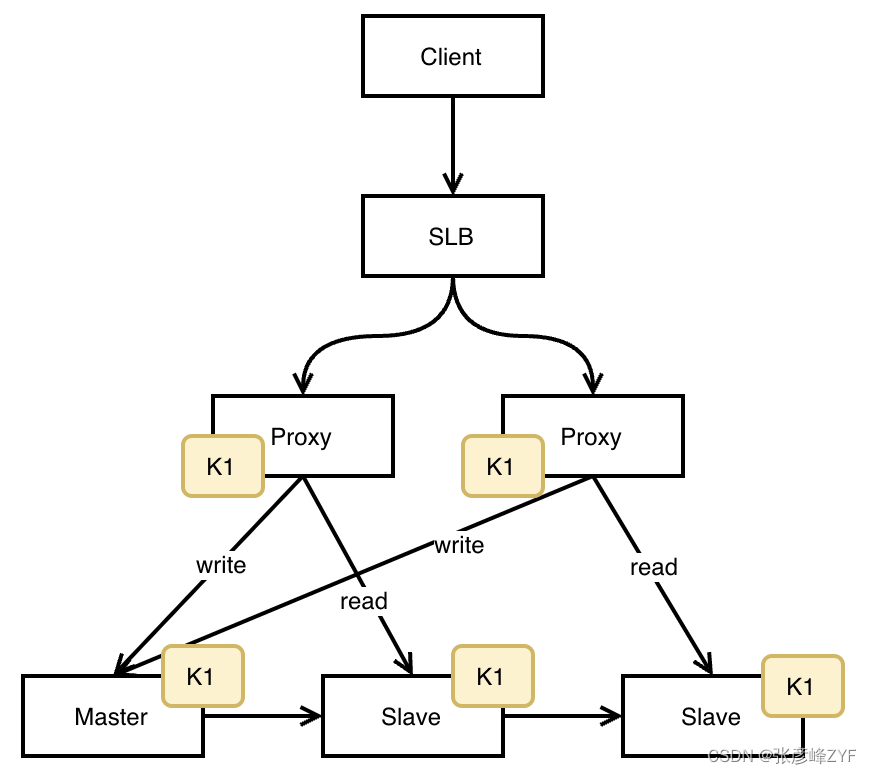
多副本策略的基本思路是为热点 key 创建多个副本,并将这些副本分布在不同的缓存节点上。客户端在读取数据时,可以随机选择一个副本节点进行读取,从而分散读取请求,减轻单个节点的压力。多副本策略的实现需要解决以下几个问题:
- 副本创建和同步:需要确保热点 key 的多个副本在创建后能够及时同步更新,以保证数据一致性。
- 读取请求分发:客户端在读取数据时,需要能够随机选择一个副本节点进行读取。
- 一致性保证:需要处理多副本之间的数据一致性问题,尤其是在写操作较多的场景下。
以下是一个简单的多副本策略实现示例,基于 Redis 的主从复制机制:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* @program: zyfboot-javabasic
* @author: zhangyanfeng
* @create: 2013-03-24 21:12
**/
public class MultiReplicaCache {
private static final int NUM_REPLICAS = 3;
private static final List<JedisPool> replicaPools = new ArrayList<>();
private static final Random random = new Random();
static {
for (int i = 0; i < NUM_REPLICAS; i++) {
JedisPool pool = new JedisPool(new JedisPoolConfig(), "localhost", 6379 + i);
replicaPools.add(pool);
}
}
public static void set(String key, String value) {
try (Jedis jedis = replicaPools.get(0).getResource()) {
jedis.set(key, value);
}
for (int i = 1; i < NUM_REPLICAS; i++) {
try (Jedis jedis = replicaPools.get(i).getResource()) {
jedis.slaveof("localhost", 6379);
}
}
}
public static String get(String key) {
int replicaIndex = random.nextInt(NUM_REPLICAS);
try (Jedis jedis = replicaPools.get(replicaIndex).getResource()) {
return jedis.get(key);
}
}
public static void main(String[] args) {
String key = "hot_key";
String value = "hot_value";
MultiReplicaCache.set(key, value);
System.out.println("Cache value: " + MultiReplicaCache.get(key));
}
}
可以看到直接的优点是:1.分散读取压力:多个副本可以显著分散读取请求,减少单个节点的压力;2.提高读取性能:通过多副本并行读取,提高系统的整体读取性能。
但重点需要关注其存在的两大基本问题:
- 一致性问题:多副本之间的数据同步可能会导致一致性问题,特别是在写操作频繁的情况下。
- 资源消耗增加:创建多个副本会增加存储和网络资源的消耗。
(三)解决策略三:热点 Key 拆分与动态分散
动态分散热点 key 的基本思路是在存储热点 key 时,将其拆分成多个子 key,并将这些子 key 分布到不同的分片上进行存储。在读取数据时,通过组合子 key 的结果来还原原始数据。这种方法可以显著分散对单个热点 key 的访问压力。
实现热点 key 动态分散思路:
- 拆分热点 Key:将一个热点 key 拆分成多个子 key。
- 分布式存储子 Key:将子 key 分布到不同的分片上进行存储。
- 组合读取子 Key:在读取数据时,通过组合子 key 的结果来还原原始数据。
简单实现如下:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* @program: zyfboot-javabasic
* @author: zhangyanfeng
* @create: 2013-03-24 21:35
**/
public class HotKeyDistribution {
private static final int NUM_PARTS = 5;
private static final List<JedisPool> shardPools = new ArrayList<>();
private static final Random random = new Random();
static {
for (int i = 0; i < NUM_PARTS; i++) {
JedisPool pool = new JedisPool(new JedisPoolConfig(),
"localhost", 6379 + i);
shardPools.add(pool);
}
}
public static void set(String key, String value) {
int partLength = value.length() / NUM_PARTS;
for (int i = 0; i < NUM_PARTS; i++) {
String partKey = key + "_" + i;
String partValue = value.substring(i * partLength,
(i + 1) * partLength);
try (Jedis jedis = shardPools.get(i % shardPools.size()).getResource()) {
jedis.set(partKey, partValue);
}
}
}
public static String get(String key) {
StringBuilder value = new StringBuilder();
for (int i = 0; i < NUM_PARTS; i++) {
String partKey = key + "_" + i;
try (Jedis jedis = shardPools.get(i % shardPools.size()).getResource()) {
value.append(jedis.get(partKey));
}
}
return value.toString();
}
public static void main(String[] args) {
String key = "hot_key";
String value = "this_is_a_very_hot_key_value_with_large_size";
HotKeyDistribution.set(key, value);
System.out.println("Cache value: " + HotKeyDistribution.get(key));
}
}
四、总结
高并发场景下的热点 key 问题是分布式系统中常见的挑战之一,直接影响系统的性能和稳定性。为了有效应对这一问题,可以采用多级缓存策略、多副本策略以及热点 Key 的拆分与动态分散等多种策略。在实施过程中,需要综合考虑系统的实时性需求、成本效益和对现有架构的影响,持续优化和调整策略,以确保系统在面对复杂的业务场景时能够稳定可靠地运行,为用户提供高效的服务体验。



![[C++][设计模式][备忘录模式]详细讲解](https://img-blog.csdnimg.cn/direct/8b380a9587904a08a6a749765c07af34.png)